Регулярные выражения в Python - основы
January 4th 2022
Регулярки в питоне
Функции для работы с регулярками живут в модуле re. Основные функции:
| Функция | Её смысл |
|---|---|
re.search(pattern, string) |
Найти в строке string первую строчку, подходящую под шаблон pattern; |
re.fullmatch(pattern, string) |
Проверить, подходит ли строка string под шаблон pattern; |
re.split(pattern, string, maxsplit=0) |
Аналог str.split(), только разделение происходит по подстрокам, подходящим под шаблон pattern; |
re.findall(pattern, string) |
Найти в строке string все непересекающиеся шаблоны pattern; |
re.finditer(pattern, string) |
Итератор всем непересекающимся шаблонам pattern в строке string (выдаются match-объекты); |
re.sub(pattern, repl, string, count=0) |
Заменить в строке string все непересекающиеся шаблоны pattern на repl; |
Пример использования всех основных функций
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match[0] if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match[0] if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m[0], 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ('\\\\\\\\foo')
Так как символ \ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида '\\\\par'. Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также. В результате с точки зрения питона '\\\\' означает просто два слеша \\. Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй. Тем самым как шаблон для регулярки '\\\\par' означает просто текст \par. Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ r, что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)». Соответственно можно будет писать r'\\par'.
Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр
flags, что несколько изменит режим работы регулярок. В качестве значения нужно передать сумму выбранных констант, вот они: | Константа | Её смысл |
|---|---|
re.ASCII |
По умолчанию \w, \W, \b, \B, \d, \D, \s, \S соответствуют все юникодные символы с соответствующим качеством. Например, \d соответствуют не только арабские цифры, но и вот такие: ٠١٢٣٤٥٦٧٨٩. re.ASCII ускоряет работу, если все соответствия лежат внутри ASCII. |
re.IGNORECASE |
Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно |
re.MULTILINE |
Специальные символы ^ и $ соответствуют началу и концу каждой строки |
re.DOTALL |
По умолчанию символ \n конца строки не подходит под точку. С этим флагом точка — вообще любой символ |
import re
print(re.findall(r'\d+', '12 + ٦٧'))
# -> ['12', '٦٧']
print(re.findall(r'\w+', 'Hello, мир!'))
# -> ['Hello', 'мир']
print(re.findall(r'\d+', '12 + ٦٧', flags=re.ASCII))
# -> ['12']
print(re.findall(r'\w+', 'Hello, мир!', flags=re.ASCII))
# -> ['Hello']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя'))
# -> ['ааааа', 'яяяя']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя', flags=re.IGNORECASE))
# -> ['ОООО', 'ааааа', 'ЫЫЫЫ', 'яяяя']
text = r"""
Торт
с вишней1
вишней2
"""
print(re.findall(r'Торт.с', text))
# -> []
print(re.findall(r'Торт.с', text, flags=re.DOTALL))
# -> ['Торт\nс']
print(re.findall(r'виш\w+', text, flags=re.MULTILINE))
# -> ['вишней1', 'вишней2']
print(re.findall(r'^виш\w+', text, flags=re.MULTILINE))
# -> ['вишней2']
Скобочные группы (?:...) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора or, который записывается с помощью символа |. Так, некоторая строка подходит к регулярному выражению A|B тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений A или B. Например, отдельные овощи в тексте можно искать при помощи шаблона морковк|св[её]кл|картошк|редиск.
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами - или :. Например, 01:23:45:67:89:ab. Каждый отдельный символ можно задать как [0-9a-fA-F], и можно весь шаблон записать так:
[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка (?:...). Можно писать круглые скобки и без значков ?:, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если REGEXP — шаблон, то (?:REGEXP) — эквивалентный ему шаблон. Разница только в том, что теперь к (?:REGEXP) можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
Скобки плюс перечисления
Также скобки (?:...) позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон (?:он|тот) (?:шёл|плыл) соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом он шёл|он плыл|тот шёл|тот плыл.
Ещё примеры
| Шаблон | Применяем к тексту |
|---|---|
(?:\w\w\d\d)+ |
Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. |
(?:\w+\d+)+ |
Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. |
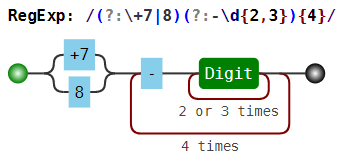
(?:\+7|8)(?:-\d{2,3}){4} |
+7-926-123-12-12, 8-926-123-12-12 |
(?:[Хх][аоеи]+)+ |
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
\b(?:[Хх][аоеи]+)+\b |
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |